




Tome 2 : Le problème de la qualité des données.
La qualité des données est un problème majeur dans le monde de la donnée, et plus particulièrement dans le domaine des Ressources Humaines car la digitalisation des processus (à travers les SIRH) induit une multiplication des erreurs due à la décentralisation de la gestion administrative et des processus de gestion des talents vers les collaborateurs plutôt que les RH.
Selon leur complexité, il est parfois très fastidieux et chronophage de détecter et de réparer ces erreurs, engendrant une perte de productivité.
C’est pourquoi Althéa s’est penché sur cette problématique afin d’y apporter, grâce à son expertise, une solution pérenne et efficace basée sur le Machine Learning.
Quels sont les types d’erreurs qui peuvent exister au sein de nos données ?
De nombreux formulaires ou fichiers de données sont encore remplis à la main. L’Humain n’étant pas infaillible pour diverses raisons, il est possible qu’il laisse passer une information incorrecte.
Voici les plus courantes :
- une entrée manuelle par un utilisateur (fautes de frappe, non-respect de la casse) ;
- une information incomplète partiellement ou totalement (aussi appelée « trou ») ;
- une valeur ambiguë souvent liée au format de la donnée (format d’un numéro de téléphone) ;
- une valeur dans une autre langue ou unité (salaire annuel en plusieurs devises, motifs d’absence en plusieurs unités temporelles).
Cela peut tout aussi bien venir de moyens technologiques comme la Reconnaissance Optique de Caractères permettant d’extraire les informations d’un document au format PDF (bulletin de paie, CV). Mais en fonction des méthodes utilisées, les informations en sortie peuvent être plus ou moins précises avec potentiellement des erreurs.
Quelles sont les technologies actuellement utilisées afin de détecter ces erreurs ?
Les ETL (pour « Extract Transform Load ») ou extracto-chargeurs sont les logiciels les plus utilisés lors de missions de reprise de données. Ils permettent entre autres de transformer massivement des données en suivant des règles de transcodification depuis une ou plusieurs sources de données (généralement des bases de données) vers une autre.
Ce type d’activités est en général chronophage et sujet à de nombreuses erreurs. De ce fait, l’utilisation des ETL est privilégiée par les entreprises, mais la vérification de la qualité des données passe par l’application de règles assez simples :
- Le contrôle et le remplacement de cellules vides avec une valeur par défaut
- Le contrôle de la cohérence des données (vérifier si les valeurs d’une colonne « Date de naissance » sont cohérentes par rapport au format attendu, par exemple).
Nous pouvons aussi noter l’utilisation de macros Excel ayant la même finalité mais impliquant un déploiement plus complexe.
Ces techniques fonctionnent en principe mais sont assez limitées dans leur utilisation. En effet, elles ne détectent que des erreurs assez simples mais ne permettent pas de vérifier la véracité des informations sur des erreurs plus complexes, notamment celles issues de données corrélées :
- Sexe – Numéro de sécurité sociale
- Quotité de travail – Nombre d’heures par mois
- Matricule – Type d’horaire
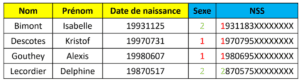
Ici, il serait par exemple long et compliqué de vérifier la pertinence de chaque triplet « Nom – Prénom – Date de naissance » et de chaque doublet « Sexe – NSS » à l’aide de macros Excel ou d’ETL car il peut y avoir une multitude d’erreurs différentes au sein de ces données.
Comment le Machine Learning peut-il améliorer la détection d’anomalies ?
Les données issues d’extractions de systèmes SIRH sont sensibles à l’apparition d’anomalies peu visibles au premier abord.
Nous avons pu constater des récurrences évidentes sur le fait que certaines colonnes au sein d’un fichier pouvaient avoir une influence sur d’autres. On parle alors de « liens » ou de « connexions ».

Le processus de détection d’anomalies via Machine Learning se décompose en 4 étapes :
- Tout d’abord, le service ayant le besoin de vérifier la qualité de ses données, indique quels types de fichiers (fichier de paie, fichier de GA, fichier de pointage, etc) il souhaite pouvoir analyser. Cela permettra de noter les spécificités fonctionnelles et techniques des données, qui seront utiles pour le paramétrage de l’outil.
- Une discussion ensuite est menée avec un expert métier afin d’établir les « connexions » entre les colonnes au sein des fichiers. C’est une étape cruciale qui déterminera la qualité des résultats obtenus en sortie de l’outil.
- Puis, notre expertise métier rentre en jeu en paramétrant l’outil de sorte à ce qu’il appréhende les données à analyser de manière optimale (transcodifier certaines données, indiquer si le délimiteur d’un nombre est un point ou une virgule, indiquer s’il faut tenir compte d’exceptions données par les experts métiers, indiquer le format de date à utiliser, etc)
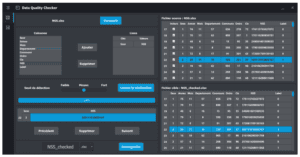
- Enfin, une fois l’outil prêt, l’utilisateur pourra visualiser les résultats sous forme d’un tableau ou sous forme graphique. Il pourra interagir avec une interface ludique afin de corriger les données par lui-même.
Le produit finalisé et customisé permet aux équipes métiers référentes d’allouer moins de temps et d’être plus efficaces sur la vérification de la qualité de leurs données avec un meilleur taux de détection.
Après analyse, nous estimons un gain de productivité d’environ 70 % comparé aux méthodes traditionnelles.
Conclusion
La problématique de la qualité des données est de plus en plus importante avec des besoins grandissants., la masse de données gérée dans le monde ayant été multipliée par 4 en 5 ans (IDC France et Statista).
De ce fait, les analyses menées avec les méthodes actuelles ne permettent pas de détecter les typologies d’erreurs les plus complexes.
Ces erreurs sont la plupart du temps les plus importantes qualitativement et peuvent être révélées grâce aux méthodes de détection d’anomalies par Machine Learning.
Althéa développe donc un outil, pour l’instant focalisé sur le contrôle de paie, visant à détecter les erreurs qui pourraient s’être glissées dans un fichier plat (taux de prélèvement à la source, cotisations manquantes, …). Cette technologie, qui se base sur les algorithmes de détection d’anomalies, est un enjeu majeur pour les collaborateurs RH-Paie.
A suivre dans le prochain tome…
