Reprise des données : une formule pour… économiser 80% de temps ? Mythe ou réalité ?

Tous les projets de systèmes d’information passent par-là : l’étape de reprise des données dans un nouveau système d’information RH, Finance, Achat ou autre reste un moment crucial pouvant faire basculer le projet dans une réussite immédiate ou, au contraire, dans un enchaînement de retards mettant en cause les dates prévues de go-live.
Guidés par une approche one-shot, au sens où une reprise des données n’a pour but que d’être faite une fois, nombreux sont les projets qui sous-estiment les moyens humains tout comme l’outillage qui pourrait tout au moins sécuriser, et au mieux constituer une première forme d’approche pérenne pour gouverner sa donnée.
Dans un chantier de reprise des données, la plupart des extractions se font en silos avec des tirs de reprise. Selon les projets et les équipes, des vérifications de qualité de donnée peuvent se faire ou non, suivies d’allers-retours pour corriger la qualité de la donnée. Dans des contextes où plusieurs acteurs sont impliqués, qu’ils soient des pays, des filiales ou toute autre forme organisationnelle, la charge de travail peut vite s’accumuler et les priorités se réorganiser tout aussi rapidement, générant une course contre la montre pleine d’imprévus. La maîtrise d’ouvrage ou la maîtrise d’œuvre du projet, interne ou externe, se retrouve bien souvent submergée avec un défi de double voir triple nature :
- Un défi technique : transcodifier, mettre en qualité, et charger des templates avec des données, très souvent manuellement ou avec des outils sous-optimaux (fichiers Excel volumineux)
- Un défi organisationnel : au-delà de la tâche technique, la correspondance quasi permanente avec un nombre rapidement élevé d’acteurs métiers responsables de la donnée est à orchestrer en concomitance avec l’avancement de la reprise
- Un défi culturel : dans les projets de grande envergure internationaux ou avec des entités intégrées par fusion-acquisition, l’alignement des acteurs métiers pose une complexité supplémentaire.
Tous les acteurs gravitant autour des projets, qu’ils soient AMOE, AMOA ou clients, sont conscients de l’énorme risque posé par cette phase critique. Une étape de reprise des données mal anticipée risque un dépassement de budget de 100%. Et si on ne dépasse pas le budget, il faut arbitrer sur autre chose : bien souvent il s’agit de la profondeur de l’historique de reprise, ce qui est un compromis fort sur la future expérience employée. Il existe pourtant des moyens de passer outre ces risques et de sécuriser le processus de reprise. Nous avons mis en œuvre des moyens de modération de ces risques lors de nos missions d’assistance à la reprise des données faites pour le compte de plusieurs de nos clients.
En particulier, nous avons réalisé, pour un grand acteur de l’exploitation de transports (30 000 paies en France et plusieurs filiales réparties sur tout le territoire) un outil de mise en qualité des données automatisant les contrôles de qualité et s’imposant comme l’interface unique de tous les contrôles de qualité, quelle que soit la division ou la filiale concernée.
Le concept est simple :
Recueillir auprès des métiers les contrôles sur la qualité de données à porter. Ces derniers déterminent des contrôles d’intégrité (contrôle de la longueur d’un champ, vérification d’un code pays…) ou des contrôles de cohérence (cumuls de paie, date d’ancienneté entité cohérente par rapport à la date d’entrée groupe, etc) ainsi que le format des fichiers de données.
Construire un outil entièrement no-code sous la forme d’une page web à disposition des métiers portant ses contrôles en automatisé, en y téléchargeant seulement le fichier qui a besoin d’être contrôlé.
Mettre à disposition ce site, avec le concours de la DSI, sur un serveur cloud interne à l’entreprise, et y former les data owners de chaque entité.
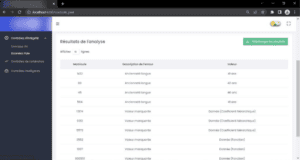
Visuel de l’outil de contrôle développé
Le processus de contrôle est ainsi porté d’une dizaine de minutes par fichier à moins de deux minutes. Et voilà, nous les tenons, nos 80% ! Mais attendez, est-ce que ça ne paraît pas un peu trop simple ? Est-ce réellement cet outil qui le permet ? Une macro VBA sur un fichier Excel automatise tout autant et produit les mêmes gains, non ?
L’erreur dans ce raisonnement est de se concentrer sur des considérations uniquement techniques alors que la réponse est plus globale.
La phase de reprise des données nécessite dans bien des cas, comme nous le disions plus haut, de multiples points de contact avec les différents interlocuteurs tributaires de la connaissance la donnée. Une tâche ardue quand il s’agit parfois de manipuler plusieurs dizaines de fichier Excel dans une même journée. Et lorsque le comité de pilotage arrive et que le responsable en maîtrise d’ouvrage de la reprise des données doit rendre des comptes, constituer le reporting d’avancement de toutes les entités et tous les templates de données nécessite un effort de compilation élevé… N’est-ce pas plus pratique qu’un outil le fasse à notre place ? Avec non seulement une photo de l’état de la reprise à date mais une historisation et un reporting par type d’anomalies détectées ?
Un outillage mis à disposition sous forme d’interface web avec simple chargement des données est dérisoirement intuitif. Et bien plus simple encore qu’un tableur. Ce qui fait que les dataowners peuvent devenir les acteurs de leur propre reprise, pouvant jouer leurs propres contrôles, leurs propres transcodifications, etc. Même si un point de contact AMOA doit rester disponible pour les assister ou réaliser les contrôles, cela tend à diminuer les sollicitations qui sont faites à son égard.
Un outil web distribué permet le traitement de gros volumes de données diverses. Qui n’a jamais eu un plantage d’Excel suite à l’analyse d’un fichier un peu trop gros (rappelons qu’Excel ne peut pas traiter plus d’un million de lignes), avec éventuellement des analyses croisées entre plusieurs fichiers ou plusieurs feuilles ?
Les fonctions d’historisation permettent de sauvegarder le résultat des contrôles, les fichiers (source comme cible) et de « rejouer » le contrôle si nécessaire et autant de fois que nécessaire en un clic.
Et enfin…. Quelques basiques d’Excel : les macros n’ont pas de fonction « retour arrière »… ce qui n’aide pas si on se rend compte d’une erreur après avoir fait tourner une macro. Elles ne traitent pas non plus de sources de données d’autres formats, certains parfois fréquents : .xml, .json, .pdf, .txt… Ce que notre outil fait.
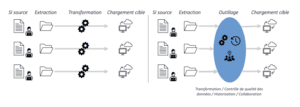
Illustration des deux méthodes
N’oublions pas non plus qu’entre différents projets avec un même éditeur, les modèles de données utilisées sont souvent similaires. Ainsi, les cycles de développement d’un outil tel que nous le proposons à nos clients sont très courts (et continuent de se raccourcir).
Enfin, il est important de noter un dernier point et non des moindres : l’avènement d’un nouveau SI rebat souvent les cartes de l’organisation qui l’entoure, et notamment de la gouvernance de la donnée. Un outillage tel que nous le décrivons permet de déléguer intuitivement et avec contrôle de charge les contrôles de qualité de données et de sensibiliser les métiers à leur importance. Une donnée bien qualifiée et mise en qualité, c’est une donnée que l’on peut valoriser et faire fructifier.
Une bonne anticipation d’un projet de reprise des données autour d’un outil permet de sécuriser et de considérablement fluidifier son développement. Dans cette quête, la DSI reste la meilleure alliée de la MOA et du métier afin d’aider au déploiement de cet outil sur le domaine interne en ouvrant l’espace machine nécessaire. Cela nécessite quelques jours d’investissement de la DSI en début de projet, mais les bénéfices en termes de respect des délais, de sollicitation des ressources et de qualité des données pour l’équipe projet et les utilisateurs finaux en sont décuplés. Et le prolongement de cette approche de mise en qualité continue en run dans une approche datalake devient naturelle… Un pas de plus vers l’organisation « data-driven » que toute entreprise veut atteindre en 2023.
En résumé :

Nous écrire


